The Data layer
The Data layer
What is the Data layer
The data layer holds application data and business logic. This allows the data layer to be used on multiple screens
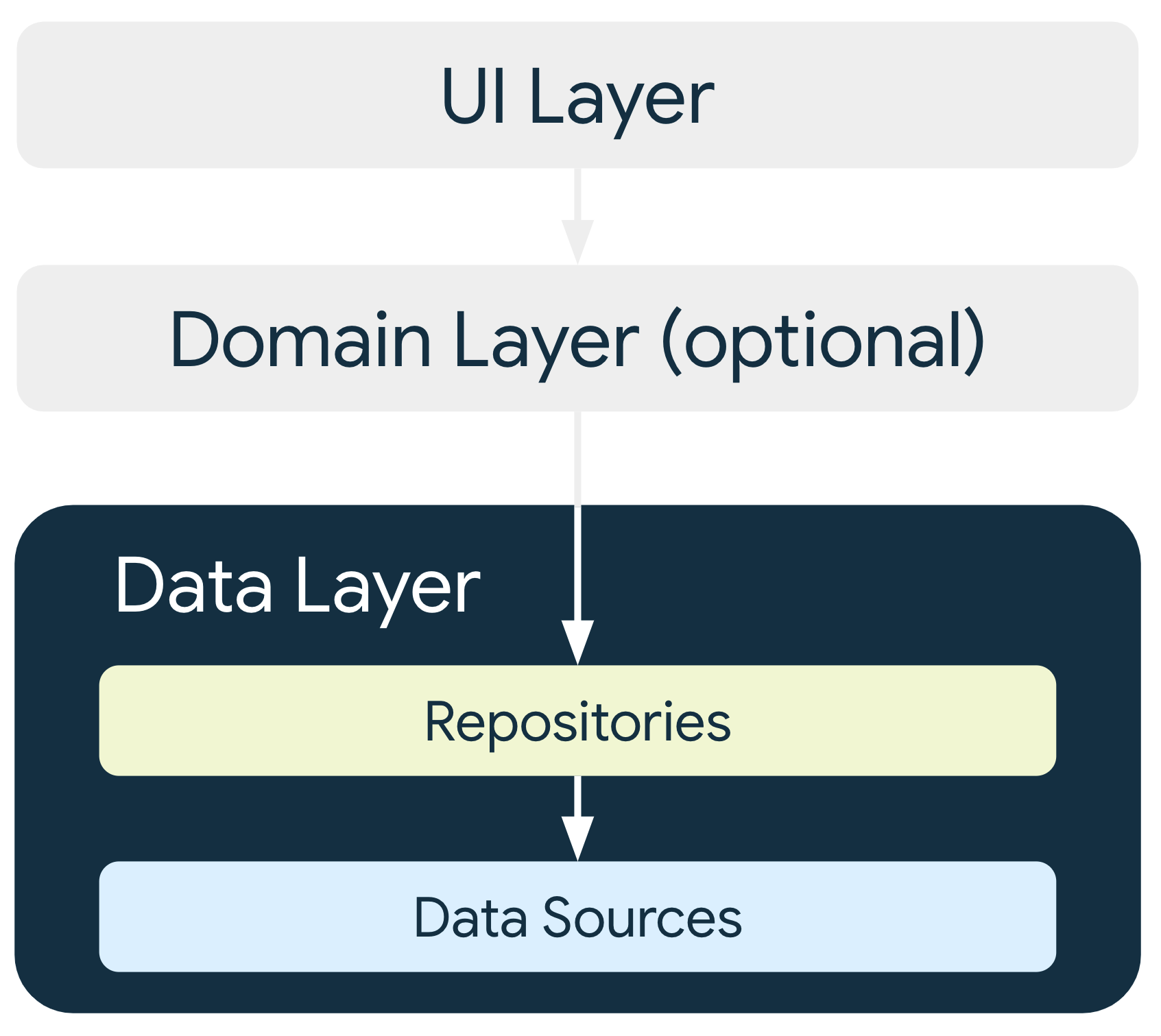
Main Components
The data layer is made of repositories that can contain from zero to many data sources, this repositories are used either by the domain layer or the data layer.
Repositories
A repository has data sources and exposes them to the other layers. This repositories are created for each different type of data that you app has this can look like:
A user Repository that exposes methods to
updateandgetthe user data, either from the network source or the local source
As you can see, a repository handles a single type of data and can determine when to get or set to different data sources. They are also responsable for:
- Resolving conflicts between multiple data sources
- Centralising changes to data.
- Containing business logic.
Data Sources
The data source exposes methods to get the latest data from its respective source.
Best practices
Multiple levels of repositories
In some cases involving more complex business requirements, a repository might need to depend on other repositories. This could be because the data involved is an aggregation from multiple data sources, or because the responsibility needs to be encapsulated in another repository class.
For example, a repository that handles user authentication data, UserRepository, could depend on other repositories such as LoginRepository and RegistrationRepository to fulfill its requirements.
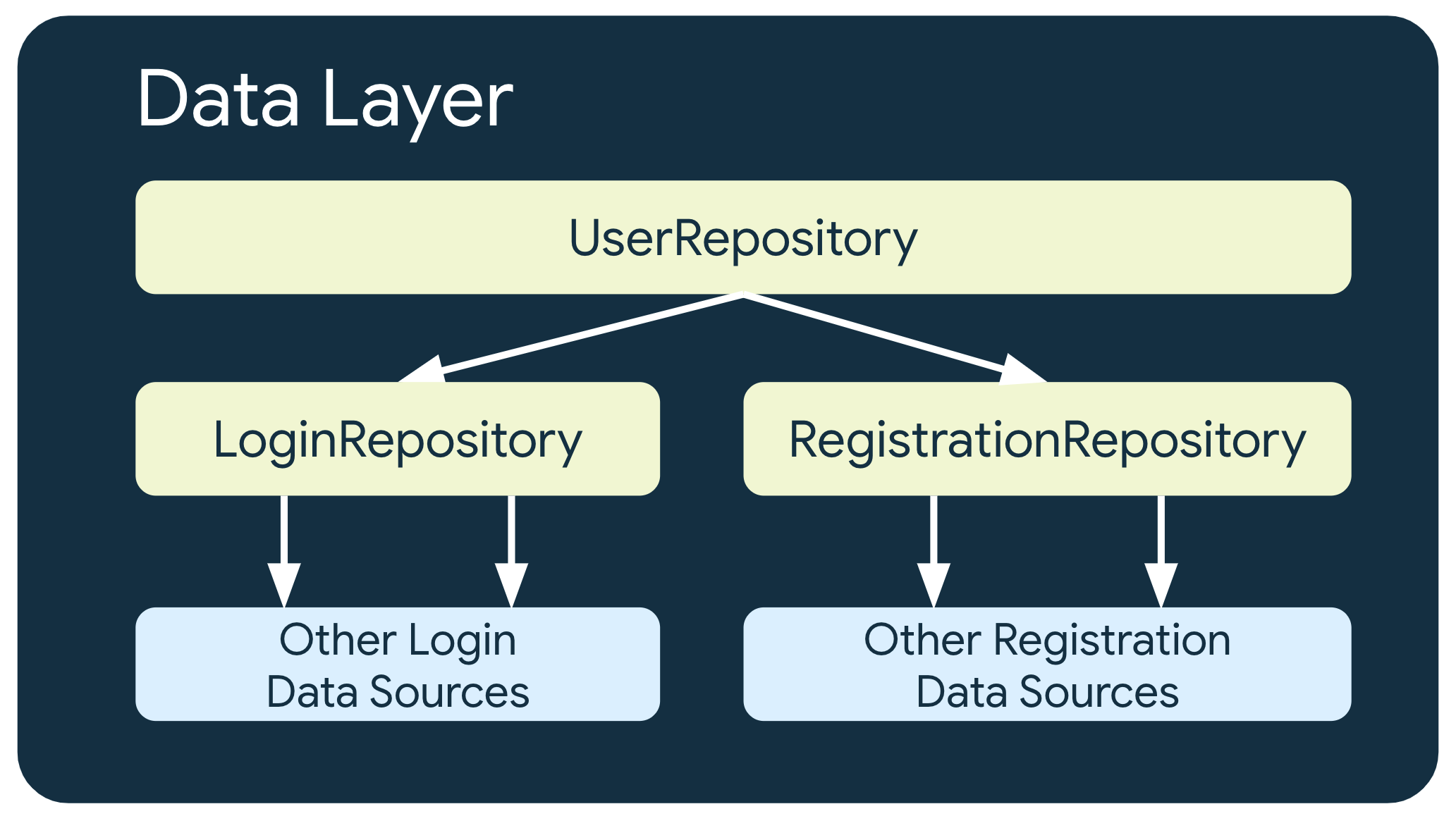
Note: Traditionally, some developers have called repository classes that depend on other repository classes managers—for example,
UserManagerinstead ofUserRepository. You can use this naming convention if you prefer.
Single responsability
Each data source class should have the responsibility of working with only one source of data, which can be a file, a network source, or a local database. Data source classes are the bridge between the application and the system for data operations.
Dependency Inversion
Other layers in the hierarchy should never access data sources directly; the entry points to the data layer are always the repository classes. State holder classes (see the UI layer guide) or use case classes (see the domain layer guide) should never have a data source as a direct dependency. Using repository classes as entry points allows the different layers of the architecture to scale independently.
Immutability
The data exposed by this layer should be immutable so that it cannot be tampered with by other classes, which would risk putting its values in an inconsistent state. Immutable data can also be safely handled by multiple threads. See the threading section for more details.
Proxy to data source
Often, when a repository only contains a single data source and doesn't depend on other repositories, developers merge the responsibilities of repositories and data sources into the repository class. If you do this, don't forget to split functionalities if the repository needs to handle data from another source in a later version of your app.
Multiple sources
It's often the case that the network and local data sources retrieve different information, and you're most likely to not use all the data in a response. At minimum, it's recommended that you create new models in any case where a data source receives data that doesn't match with what the rest of your app expects.
Architecture Patterns
Relates to
References
Google's Data Layer